Not Another AI Patent Article: Data-Driven Prosecution In The Field Of Artificial Intelligence
As noted at the bottom of the page (but worth repeating here): Any views or opinions expressed by me on this blog are solely my own and do not necessarily reflect those of Oracle Corporation, its subsidiaries or affiliates, or those of Chicago-Kent College of Law. The information on this blog is intended to promote discussion--please contact a qualified patent attorney if you need any patent advice.
It is presumed that the reader of this article already has a general understanding of artificial intelligence. If not, consider Wikipedia or your search engine of choice. This article is outlined as follows:
There have been many articles written about drafting and prosecuting patent applications relating to artificial intelligence. Most of the articles are based on the practical experience of attorneys who draft patent applications, and they speak at a high level about trying to draft patent applications to comply with the relevant patent laws: mainly 101 (patent eligibility), 103 (non-obviousness), and 112 (definiteness, written description, and enablement). These laws have been around for over 150 years, and they were not significantly impacted by the field of artificial intelligence. For that reason, everyone who has taken the patent bar (a prerequisite to drafting patent applications) should already be familiar with these laws and how they are applied in a variety of scenarios. That said, the articles are a good reminder of what the laws are and how they are regularly applied.
Here are some recent example articles I found, in no particular order:
Drafting Patent Applications Covering Artificial Intelligence Systems, by Christopher J. White and Hamid R. Piroozi (Landslide January/February 2019)
How to Draft Patent Claims for Machine Learning Inventions, by Michael Borella (Patent Docs Nov. 25, 2018)
Intellectual Property Protection for Artificial Intelligence, by Frank A. DeCosta, III, Ph.D., Aliza G. Carrano (Westlaw Journal Intellectual Property, Aug. 30, 2017)
Protecting Artificial Intelligence and Big Data Innovations Through Patents: Subject Matter Eligibility, by Douglas H. Pearson, Ognian V. Shentov, Karl. A. Kukkonen III, Andrea Weiss Jeffries (Mar. 2018)
Strategies for Claiming AI Inventions in Patent Applications, by Andrew Rapacke (Aug. 2018)
I would summarize these articles as follows:
It is presumed that the reader of this article already has a general understanding of artificial intelligence. If not, consider Wikipedia or your search engine of choice. This article is outlined as follows:
- EXISTING ARTICLES ABOUT AI PROSECUTION STRATEGIES
- SUMMARY OF DATA-DRIVEN WAYS TO IMPROVE DRAFTING AND PROSECUTING AI-RELATED PATENT APPLICATIONS
- METHODOLOGY OF FINDING AI CASES
- HIGH-LEVEL METRICS FOR AI CASES
- IMPACT OF THE 2019 REVISED PATENT SUBJECT MATTER ELIGIBILITY GUIDANCE
- LAW FIRM METRICS FOR AI CASES
- TOP CLAIM LANGUAGE CLUSTERS
- TOP CLAIM TERMINOLOGY
- CLAIM LENGTH CONSIDERATIONS FOR AI CASES
- PRIORITY ISSUES FOR AI CASES
- CONCLUSIONS
There have been many articles written about drafting and prosecuting patent applications relating to artificial intelligence. Most of the articles are based on the practical experience of attorneys who draft patent applications, and they speak at a high level about trying to draft patent applications to comply with the relevant patent laws: mainly 101 (patent eligibility), 103 (non-obviousness), and 112 (definiteness, written description, and enablement). These laws have been around for over 150 years, and they were not significantly impacted by the field of artificial intelligence. For that reason, everyone who has taken the patent bar (a prerequisite to drafting patent applications) should already be familiar with these laws and how they are applied in a variety of scenarios. That said, the articles are a good reminder of what the laws are and how they are regularly applied.
Here are some recent example articles I found, in no particular order:
Drafting Patent Applications Covering Artificial Intelligence Systems, by Christopher J. White and Hamid R. Piroozi (Landslide January/February 2019)
How to Draft Patent Claims for Machine Learning Inventions, by Michael Borella (Patent Docs Nov. 25, 2018)
Intellectual Property Protection for Artificial Intelligence, by Frank A. DeCosta, III, Ph.D., Aliza G. Carrano (Westlaw Journal Intellectual Property, Aug. 30, 2017)
Protecting Artificial Intelligence and Big Data Innovations Through Patents: Subject Matter Eligibility, by Douglas H. Pearson, Ognian V. Shentov, Karl. A. Kukkonen III, Andrea Weiss Jeffries (Mar. 2018)
Strategies for Claiming AI Inventions in Patent Applications, by Andrew Rapacke (Aug. 2018)
I would summarize these articles as follows:
- A general introduction to artificial intelligence,
- Caution to satisfy 101 (patent eligibility) by claiming a technical point of novelty,
- Caution to satisfy 103 (non-obviousness) by not claiming something obvious, and
- Caution to satisfy 112 (definiteness, written description, and enablement) by drafting clear claims and a supporting description.
A. What can we learn from the existing material?
The problem is that, except for the general introduction to artificial intelligence, most of these points apply in roughly the same way they have always applied. Patent applicants need to satisfy these requirements regardless of which field they are working in, and those drafting patent applications have already taken a test to verify they understand these basic laws. Patent attorneys all have different levels of skill in this area, but their levels of skill cannot be determined based on whether or not they wrote an article with the bullet points above.
Instead, patent attorneys' level of skill can be determined by looking at their patent prosecution statistics in the field of artificial intelligence, or by looking at patent applications or office action responses they have personally drafted. There is a level of opaqueness in the patent practice that leaves clients in the dark when they search for a patent attorney. If clients cannot learn much from the bullet points above about who to hire, and if patent attorneys should already know the bullet points above, then there is not much left for a target audience to learn (after reading at least one article about AI and patents).
B. Who can learn something different from this article?
The target audiences for this article are patent attorneys drafting and prosecuting cases relating to artificial intelligence, as well as clients reviewing their work. This article approaches drafting and prosecuting claims relating to artificial intelligence from a big data perspective. I conducted several big data studies of AI-related patent applications, and I learned what claimed content and what claim terminology have had the most (and least) success at the patent office as well as which law firms have had the most (and least) success so far (for this sample). Although I have drafted thousands of claims for hundreds of patent applications, many of which relate to artificial intelligence and some for which I was a co-inventor, this article does not rely on my conventional wisdom to draw conclusions. Please see articles like the ones above if you are interested in conventional wisdom.
This article brings unconventional wisdom to the table by using algorithms to learn patterns that are not detectable to human patent attorneys working on the front lines of patent drafting, or by clients reading the tea leaves while working case-by-case (or maybe who have never even filed a case). By posting that unconventional wisdom here, I'm hoping that patent attorneys will use it to draft better patent applications that are easier to understand, easier to examine, and more closely tied to the technology that was actually invented. I'm also hoping that clients will research their law firms carefully based on a growing knowledge base before making their investment in intellectual property. Currently, the quality of patent drafting and subsequent prosecution is so varied that, based on historical statistics for different applicants or law firms and for similar technologies, some patent applicants have a very low chance of getting a patent while others have greater than a 90% chance of getting a patent.
2. SUMMARY OF DATA-DRIVEN WAYS TO IMPROVE DRAFTING AND PROSECUTING AI-RELATED PATENT APPLICATIONS
Based on a new data-driven study of existing patent claims after content clustering algorithms and term frequency algorithms were applied, several practical data-driven conclusions were reached about desirable and undesirable claiming strategies for AI-related cases.
These data-driven conclusions are summarized as follows:
These data-driven conclusions are summarized as follows:
A. To the extent practical and still valuable, steer claim language toward (e.g., by including relevant key terms and concepts):
- Hard technologies like self-driving cars, medical imaging, IoT, or cloud infrastructure, where claims have average allowance rates in the 80% to 90% range,
- Neural networks or changes made to other machine learning algorithms (as applied), where claims have average allowance rates above 80%,
- Distinctive details on training and using a machine learning model, where claims have average allowance rates above 80%,
- Algorithmic and non-human aspects of speech recognition, where claims have average allowance rates near 80%,
- Distinctive details on the spatial relationship of components, where related terms have average allowance rates in the 70% to 90% range,
- Distinctive details on how data is stored relative to other data, where related terms have average allowance rates in the 70% to 90% range,
- Distinctive details on how data or resources are distributed across a network, where related terms have average allowance rates in the 75% to 85% range, and
- Distinctive details of a novel algorithm (as applied), where related terms have average allowance rates in the 70% to 90% range.
- Aspects of the invention focused on finance, where related terms have allowance rates in the 50-70% range,
- Vague or inflated benefits of the invention (termed "squishy puffery" in Section 8), where related terms have average allowance rates in the 50-70% range,
- User interface functionality as opposed to how that functionality is achieved behind-the-scenes, where claims have allowance rates near 60%,
- Aspects focused on human activity, including user interaction, where related terms have average allowance rates in the 60-70% range,
- Basic signal and image processing or format conversion, where claims have average allowance rates near 70%,
- Aspects focused on content management or content licensing, where claims have average allowance rates near 70%, and
- Aspects focused on high-level social relationships, where related terms have average allowance rates near 70%.
D. Beware of intervening prior art if you filed a priority application, given that 62.7% of the AI-related patent applications claimed priority to an earlier filing and 26.7% of provisional applications (from a different study covering AI and non-AI cases alike) are missing a quarter or more of the terminology from the first non-provisional claim.
E. Work with attorneys who are experienced in successfully drafting and prosecuting AI-related cases. Top firms had allowance rates above 90%, while other firms had allowance rates as low as 0-63%. Also, top firms received, on average, less than one office action (e.g., a communication from the patent office rejecting the claims), while other firms received, on average 2-3 office actions from the patent office. These high-level statistics should be considered only after a deeper investigation into the underlying reasons for abandonment of relevant applications or extended prosecution for relevant applications, as many of these reasons may be unrelated to the law firm or practitioner handling the matter.
3. METHODOLOGY OF FINDING AND CLUSTERING ARTIFICIAL INTELLIGENCE CASES

In the study, I searched CPA Innography for all U.S. published patent applications filed and with priority post-Alice (6/20/14 and later) (pending, patented, and abandoned), where any one or more of the following words ("AI keywords") was present in the title, abstract, or claims:


On Jan. 7, 2019, the U.S. Patent Office published The 2019 Revised Patent Subject Matter Eligibility Guidance, which severely limits the ability of examiners to reject cases under 35 U.S.C. 101. Overall allowance rates have increased since the guidance, reaching a historic high of 76.8% in July of 2019, as shown by the USPTO here. To check whether the Revised Patent Subject Matter Eligibility Guidance has changed any of these high-level metrics, I also compiled the sample's metrics for cases finally disposed (granted or abandoned) since February of 2019.
Since Feb. 2019, the allowance rate for AI-related applications is 82.2%, which is almost identical to the allowance rate for the full sample. Based on this finding, I concluded that the Guidance had little overall impact on the allowance of AI-related applications. That said, I was surprised to see so many cases finally disposed this year. That is perhaps because the filing rate of AI cases increased considerably over the span of the sample.
 6. LAW FIRM METRICS FOR AI CASES
6. LAW FIRM METRICS FOR AI CASES
PatentAdvisor provides a Normalized Law Firm field. The tool gathers the representative agent data from the Patent Application Information Retrieval (PAIR) database and cleans up the agent data to address minor law firm misspellings. Because of this feature, law firm data can be easily viewed and compared.
A. Allowance Rates For Law Firms' Cases In The AI Sample
The sample of 24,848 AI-related cases determined in Innography (8,726 of which were finally disposed (see Section 4 above)) were imported into PatentAdvisor, and the Normalized Law Firm field was exported along with the case status, the number of OAs (Office Actions), and the number of RCEs (Requests for Continued Examination). The allowance rate was determined by dividing the number of granted cases by the number of finally disposed cases (granted and abandoned) for each Normalized Law Firm. The average OAs and average RCEs were determined by averaging the number of OAs and RCEs for each application (both pending and finally disposed applications) mapped to the same Normalized Law Firm. The charts below also show average OAs and RCEs for just the finally disposed cases mapped to the same Normalized Law Firm.
When sorting the data by allowance rate, some firms had allowance rates above 90%, while other firms had allowance rates as low as 0-63%. The chart below shows the highest allowance rates for law firms with more than 25 applications granted the AI sample. As shown, Mahamedi IP Law LLP Uber, Lempia Summerfield Katz, Young Basile, Wolfe Sadler Breen Morasch & Colby, Wilson Sonsini Goodrich & Rosati, and Ryan Mason & Lewis all had allowance rates of 100% for the sample, with 25-40 cases finally disposed. Also impressive were Tutunjian & Bitetto, Sheridan Ross, and Greenblum & Bernstein, with allowance rates near 100%.

Note that allowance rates are not always in control of the law firms. For example, a law firm may have a lower allowance rate if the law firm is prosecuting difficult cases or cases targeting marginal innovation, or if the law firm is working with clients who insist on abandoning cases despite good drafting and potentially good value (often due to changing business needs and financial capabilities). The client is often making the final decision on whether to pursue or abandon a case, and, to that end, the law firm is merely carrying out the client's instructions. That said, the allowance rate is impacted by the law firm, as the law firm drafts cases and is charged with zealously representing clients during prosecution with the USPTO.
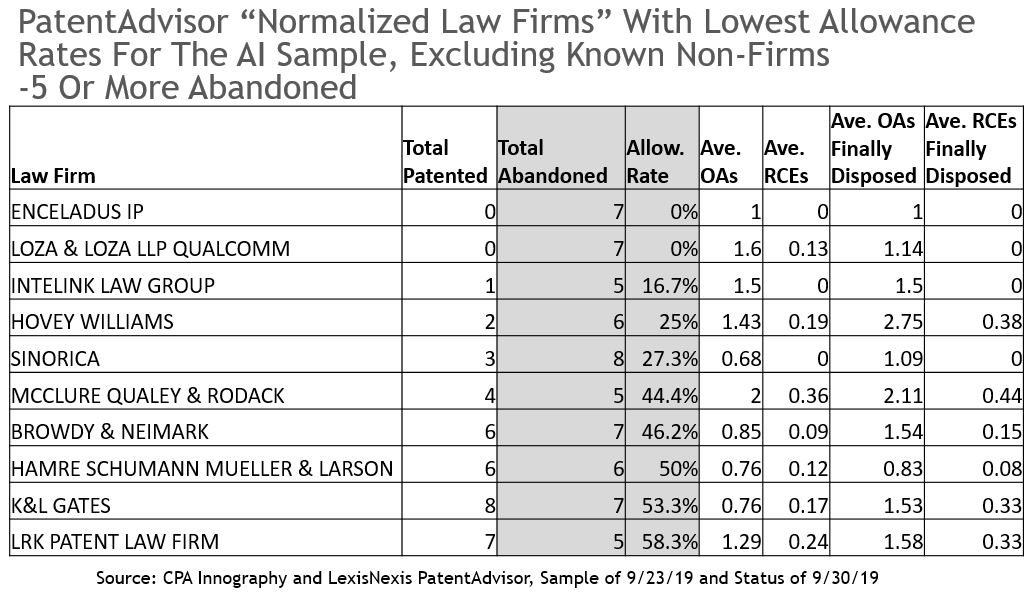
Some law firms did not have as many granted cases in the sample of 8,726 finally disposed cases. Since the AI sample is a small subset of the hundreds of thousands of applications filed at the USPTO each year, it is important to understand that many of these law firms handle a wide variety of cases that include AI-related cases and likely also large sets of cases not related to AI. The chart below shows PatentAdvisor's "Normalized Law Firms" with 5 or more abandoned cases, sorted by the lowest allowance rates for the AI sample, after excluding known non-firms. As shown, Enceladus IP and what PatentAdvisor has listed, in the “Normalized Law Firm” field, as “Loza & Loza LLP Qualcomm” each had allowance rates of 0% for 7 finally disposed cases in the sample. Intelink Law Group, Hovey Williams, Sinorica, McClure Qualey & Rodack, and Browdy & Neimark had allowance rates of less than 50% for their cases that were in the sample. Hamre Schumann Mueller & Larson, K&L Gates, and LRK Patent Law Firm fared slightly better with allowance rates between 50 and 60% for finally disposed cases in the sample.

The chart below shows PatentAdvisor's "Normalized Law Firms" with 10 or more abandoned cases, sorted by the lowest allowance rates for the AI sample, after excluding known non-firms. As shown, Stevens Law Group and Muncy Geissler Olds & Lowe had allowance rates between 60% and 70% for their cases that were in the sample. Marbury, Knobbe Martens Olson & Bear, Schwegman Lundberg & Woessner, Oblon, and Sughrue Mion had allowance rates between 70% and 80%, which is near the average allowance rate for the USPTO. Norton Rose Fulbright fared better with an allowance rate of 80%, which is very close to the average allowance rate for the cases in the AI sample. As discussed above, there are many reasons outside of a law firm's control for why a law firm could have a lower allowance rate in the AI sample.

B. Average Pendency For Law Firms' Cases In The AI Sample
As explained above, the sample of 24,848 AI-related cases determined in Innography were imported into PatentAdvisor, and the Normalized Law Firm field was exported along with the case status, the number of OAs (Office Actions), and the number of RCEs (Requests for Continued Examination). The average OAs and average RCEs were determined by averaging the number of OAs and RCEs for each application (including both pending and finally disposed applications) mapped to the same Normalized Law Firm. The average OAs and average RCEs for only the finally disposed cases are listed separately.
Office actions include communications from the patent office rejecting the claims or objecting to the claims. They typically require a response on the part of the applicant to either change the claims in light of the rejection or objection, or to explain/argue why the rejection or objection was erroneous.
Requests for Continued Examination are required to continue the back-and-forth discussion with the examiner, typically to further amend the claims, after an applicant has reached a final office action. RCEs may also be required to submit newly discovered information in an information disclosure statement, or for other reasons that are outside of the law firm's and applicant's control. Each RCE costs $1300-$1900 for large entities, but only $325 to $475 for micro entities. Different firms may, on average, serve clients who are more or less sensitive to RCE costs. This would certainly affect the firms' pendency stats (below).
The number of OAs and number of RCEs is sometimes used to roughly approximate the cost of a patent application, with average office action fees; however, different law firms charge different amounts for different tasks. For example, some law firms could charge $2000 per office action; while others could charge $6000 per office action. Some law firms charge separately for examiner interviews, while others include interview charges in a fixed-fee office action reply. For these reasons, the number of OAs and number of RCEs is not a very good approximation of cost unless you understand the law firm's practices as well as the client's policies, or unless there is a more established norm in the industry or at least among candidate firms.
Note that the number of OAs and RCEs included OAs and RCEs for pending and finally disposed (granted or abandoned) published applications. For that reason, applications in the sample that were recently published (and likely recently filed) may not have yet received many office actions. Other applications may be long-pending but never finally disposed for a variety of reasons. For example, see this article by Chad Gilles about an unusual RCE strategy. To mitigate this effect, the charts below separately list average OAs and average RCEs that occurred in just the finally disposed cases, even though the charts are sorted based on average OAs that occurred in all applications, pending and finally disposed.
Also recall that the AI sample is cut off in the sense that it includes cases filed and having priority June 20, 2014, and later (but not earlier). The currently longest pending cases at the USPTO are cases filed before June 20, 2014, but these cases were outside of the AI sample's range.
As a result at least from counting pending cases and cutting off the sample at June 20, 2014, and in light of the limited sample size, the pendency statistics presented herein should not be used to estimate the actual number of office actions expected in a given scenario with a given firm. Those numbers should instead be calculated based on factors known and specific to the given scenario, with an understanding that there is a lot of variance in these numbers case to case.
When sorting the Normalized Law Firms by the number of office actions (least to greatest), top firms received, on average, less than one office action from the patent office. Other firms received, on average, between two and three office actions or objections from the patent office. As shown in the chart below for the most efficient firms in the AI sample with greater than an 85% allowance rate and 25 issued cases, Hauptman Ham apparently had many first action allowances, with averages of 0.19 office actions per application and 0.33 per finally disposed application. Also impressive were Dinsmore & Shohl, McDonnell Boehnen Hulbert & Berghoff, Harness Dickey & Pierce, Kilpatrick Townsend & Stockton, and Fenwick & West, who all averaged less than 0.9 office actions per application in the AI sample and around 1 office action per finally disposed application in the AI sample. Also as shown, Greenblum & Bernstein, Schox, Barnes & Thornburg, and Dority & Manning all had excellent average pendencies of just under 1 office action per case and between 1 and 2 office actions per finally disposed case.

Note that the number of office actions and RCEs are not always in control of the law firms. For example, a law firm may have more office actions if the law firm is prosecuting difficult cases or cases targeting marginal innovation, or if the law firm is working with clients who insist on pursuing cases despite reasonable arguments from patent examiners (often due to the high importance and value of the case). The client is often making the final decision on whether to continue prosecution, but the number of office actions and RCEs may also be impacted depending on how the law firm drafts and prosecutes the case.
As noted above, many of these law firms handle a wide variety of cases, with a small subset being the AI-related cases in this sample. The chart below shows PatentAdvisor's "Normalized Law Firms" with 10 or more total cases, sorted by the highest average number of office actions for the AI sample, after excluding known non-firms. As shown, Rogitz, Ference, Dorian Cartwright and Bookoff McAndrews PLLC averaged near 2.5 office actions per case (between 2.4 and 2.58 office actions per case) in the AI sample. Artegis Law Group LLP Harman, Blakeley Sokoloff Taylor & Zafman, and Cascadia Intellectual Property averaged between 2.13 and 2.33 office actions per case in the AI sample; whereas, Thomas D. Harvey and Squire Patton Boggs averaged just above 2 office actions per case in the AI sample. Note again that the AI sample was sorted based on the average number of OAs ("Ave. OAs") in both pending and finally disposed (granted or abandoned) published applications, and the "Ave. OAs Finally Disposed" column includes the average number of OAs only for the finally disposed cases handled by the corresponding Normalized Law Firm in the sample.

7. TOP CLAIM LANGUAGE CLUSTERS
As explained above, this study employed a standard k-means clustering algorithm on the claims from CPA Innography to determine eleven resulting clusters. The clustering algorithm was applied to the first claim only and was blind to allowance rates, examiners, and art units. The clustering algorithm identified 11 clusters, which I have named based on the top keywords the algorithm identified for each cluster: Self-driving cars, medical imaging, neural networks, cloud services infrastructure, IoT, training and using a ML model, speech recognition, application functionality, content management, signal and image processing, and user interaction.
The top keywords for each cluster are ordered by the algorithm in terms of importance to defining the cluster as a separate cluster. For that reason, when naming the clusters, I focused mostly on the most defining keywords (occurring earlier in the list) and secondarily on the remaining keywords. Some keywords defined multiple clusters. Keywords occurring in more than 3 clusters were filtered out because they were not as helpful for understanding the cluster among the other clusters. Although I listed keywords that occurred 2-3 times, I focused mostly on the keywords that were unique to the cluster.
All clusters and top keywords were computer generated without human input. The charts below combine the cluster and keyword information with examiner statistics and art unit statistics from LexisNexis PatentAdvisor to provide unique holistic insights into prosecuting AI-related patents. One of the most surprising findings of this study, as is evident from looking at the charts below, is that observed allowance rates for AI-related applications in many clusters of the sample were well above the examiner and art unit allowance rates corresponding to where applications in the cluster were being examined. This finding contradicts the teaching of some tool vendors who suggest the outcome of a case is mostly dependent on the patent examiner.
The first chart below shows, for the top 4 clusters sorted by allowance rate ("Allow. Rate"), the prosecution statistics as well as the key terms determined by the clustering algorithm. As shown, the average examiner allowance rate ("Examiner Allow.") and average art unit allowance rate ("Art Unit Allow.") result from averaging the allowance rates for the examiners or art units for cases from the sample that were in the corresponding cluster. The examiner and art unit allowance rates are different from the actual observed allowance rates for cases in the sample because examiners and art units handle many cases outside of each corresponding cluster of the sample. Some of the cases outside of the cluster of the sample are likely cases filed on similar topics pre-Alice; whereas, other cases outside of the cluster of the sample are likely cases filed on similar or different topics and not apparently related to AI. The individual clusters are discussed in more detail below.
 Self-Driving Cars
Self-Driving Cars
I named the first cluster "self-driving cars" due to the top distinct claim terms in the cluster. The claims in that cluster clearly relate to autonomous vehicles driving on a road, as automatically determined by the clustering algorithm. Surprisingly, the 915 cases in this cluster had an allowance rate of 90.9%, which is significantly above the average for the sample. Also surprisingly, the average examiner allowance rates for the "self-driving cars" cases was 74%, which is below the average allowance rate for patented cases in the sample (despite the actual allowance rate being much higher). That said, the examiner allowance rate was still the highest among the clusters, and the art unit allowance rate was among the highest. This suggests that the self-driving cars cases (as well as other AI-related cases) are not consistently getting routed to the same group of examiners within the USPTO. If they were, the average examiner allowance rates would be closer to the observed allowance rates for the sample (in this case, 90.9%). Not surprisingly, patent eligibility issues rarely come up for the self-driving cars. From an Alice perspective, based on the data below, one could assume this area is generally quite technical.
Medical Imaging
I named the second cluster "medical imaging" because "medical" and "region" were uniquely defining to the cluster, and because other words in the cluster also fit within this paradigm. Although the observed allowance rate and average art unit allowance rate are very high, the examiner allowance rate is actually low. This means that medical imaging AI-related cases are getting routed to lower allowance examiners within art units but still getting allowed at a very high rate anyway. This also means that these examiners likely see a wide variety of technology, most of it having significantly lower allowance rates.
Neural Networks
I named the third cluster "neural networks" because it was the only cluster defined by the keyword "neural," and because other top keywords such as "network" and "layer" were consistent with this characterization. The allowance rates for neural network cases were high, despite very low examiner allowance rates, averaging 55.3% (second lowest among the clusters). Although these cases saw a slight rise in 101 rejections over medical imaging and self-driving cars, the vast majority (77.1%) still did not receive a 101 rejection during prosecution.
Cloud Services Infrastructure
The fourth cluster was challenging to pin down, as the keywords included many terms that are basic to many AI-related cases. That said, it was the only cluster defined by Cloud, and the top keywords "Service," "Request," "Network," and "Provider" fit cleanly within the field of cloud services infrastructure. These cases had a very high rate (30.2%) of 101 rejections, and low examiner and art unit allowance rates. Normally, that would lead one to believe that the observed allowance rate is also low. In this case, however, the allowance rate of 84.1% is higher than the average for the sample. This cluster is yet another indication that examiner and art unit allowance rates are not controlling the allowability of AI-related cases.
 Internet of Things (IoT)
Internet of Things (IoT)
The fifth cluster is clearly related to IoT, with "signal," "power," "robot," "controller," and "position," and even "NAN," presumably "Neighborhood Area Network." This cluster had fairly average stats among the AI-related clusters, except that cases in this cluster were least likely (10.4%) to experience a 101 rejection during prosecution. IoT-related inventions are generally very device-oriented, and it makes sense that cases in this cluster would generally pass muster under Alice.
Training and Using A Machine Learning Model
Two clusters were combined together to form the cluster named "training and using a machine learning model." One cluster was slightly more focused on training, and the other cluster was slightly more focused on using. That said, the keywords and statistics for both clusters were nearly identical. For the purposes of this study, they were merged, even though they may exhibit other differences in future studies. These cases had average allowance rates with very poor examiner, art unit, and 101 statistics. I expect that this cluster could be broken down into 10-20 further clusters with another layer of clustering in a future study. As it is, it is difficult to draw any conclusions from the general language that defines this cluster.
Speech Recognition
The seventh cluster has "speech" and "recognition" as two of the top three keywords that define the cluster. It is clear what that this cluster represents AI innovation in the area of recognizing words and meaning from spoken words. It also makes sense that this cluster has the highest rate of 101 rejections (a whopping 39.5%) among the clusters, as speech recognition in the abstract is typically a human-performed task. Also, the way humans recognize speech has some parallels to the way computers recognize speech. The human brain breaks up sounds into parts and associates those parts with meaning. When drafting a patent related to speech recognition, Alice should be considered during the drafting phase. Although there is a high rate of 101 rejections, the allowance rate for this cluster is still 78.6%, which is near the average for the overall sample. This may be partially due to favorable routing at the patent office. These cases are being routed to high allowance art units, which is helpful when dealing with 101 rejections.

Application Functionality
The eighth cluster relates to "application," "interface," "mobile," and "behavior," which has been packaged here as "Application Functionality." As would be expected by thinking of parallels within art unit 3600 independent of the AI realm, the rate of 101 rejections is relatively high (32.0%), and examiner allowance rates are relatively low (59.5%) for this cluster. That said, the AI-related cases seem to be making it through at a rate of 76.2%, which is very close to the average allowance rate across the entire patent office.
Content Management
The ninth cluster, named "content management," relates to "content," "media," "digital," and even "CLM," which presumably refers to "content license management." The rate of 101 rejections is very high (second highest among the clusters at 37.1%), with low examiner and art unit allowance rates and also relatively low observed allowance rates. Because the allowance rate of 74.9% is currently slightly below the patent office average, I would steer an application away from this cluster of AI-related technologies if practical.
Signal And Image Processing
The tenth cluster is defined by "signal," "image," and "energy," which likely places it in the realm of signal and image processing. Although this cluster does not see a high rate of 101 rejections, it still experiences a relatively low allowance rate for AI-related cases. It seems like the tie between this cluster and AI-related technologies is weak, and I would steer an application away from this cluster if practical.
User Interaction
This cluster is related to user interfaces, but it does not seem closely related to AI technologies. In order to occur in the sample, a case would need one of the AI-related keywords in the title, abstract, or claims. With low allowance rates of 71.8% and high rates of 101 rejections, this is the worst overall cluster. That said, an allowance rate of 71.8% is still not too bad in light of the average examiner allowance rates of 54.7%. This suggests that the AI-related technology potentially in these cases was helpful in securing patent protection.
8. TOP CLAIM TERMINOLOGY
As discussed above, I used a standard word stemming algorithm on the claims from CPA Innography to determine term frequencies in the issued patents and term frequencies in the abandoned applications. As used in this study, the "allowance rate of a term" is the number of granted cases that include the term in the first claim divided by the number of finally disposed cases (including granted cases and abandoned cases) that include the term in the first claim.
Unlike the other parts of this study, the word stemming portion was driven by my personal judgment on the clustering and strength of relationship among the terms in light of known laws that affect the patentability of certain types of inventions. My goal in this portion of the study was to find all terms that were uniquely related to a similar concept, starting with the terms that occurred most frequently with the highest and lowest allowance rates.
The allowance rates of various terms, as presented below, are independent of the clusters discovered in section 7. The allowance rates in this section cover the occurrences of these terms across the entire sample of AI-related cases.
Self-Driving Terms
With self-driving cars coming in as the top AI-related cluster, in terms of allowance rate, I searched the list of word stems for terms that were closely related to self-driving cars. Not surprisingly, these terms all had very high allowance rates even though they sometimes occurred outside of the self-driving cluster. Most of these terms also boosted the allowance rates even higher when they occurred in the first independent claim instead of just in the focus (title, abstract, or claims).

Spatial Terms
Spatial terms such as "shape," "reach," and "along" were associated with higher allowance rates, particularly when present in the first independent claim. For example, cases with "along" in the title, abstract, or claims, on average, had allowance rates of 88.5%, and the allowance rate increased to 89.9% when "along" was in the first independent claim.

Data Distinction Terms
Although past studies have found data storage distinctions and container-related terms to be very helpful when present in the claims, they were only slightly helpful in AI-related cases, with "object" having a slightly higher allowance rate when present in the first independent claim.

Distributed Systems Terms
There were several terms relating roughly to distributed networks, systems, or IoT that were frequent in the sample but with average allowance rates. Most notably, "status" had a higher allowance rate of 87.1% when present in the first independent claim.

Algorithm Terms
The more detailed algorithm terms, such as "neural," "anomaly," and "confidence" had higher allowance rates compared to the more general algorithm terms such as "algorithm" and "test." That said, most algorithm terms slightly boosted allowance rates when moved into the first independent claim as compared to just being in the focus (abstract, title, or claims).

Data Management or Conversion Terms
Data management and conversion terms were associated with slightly lower allowance rates than the average allowance rates for the AI sample, and these terms were not very helpful in the claims.

High-Level Social Terms
High-level social terms were also associated with slightly lower allowance rates than the average allowance rates for the AI sample. In particular, the term "social" had a 67.5% allowance rate when present in the first independent claim. This is well below the average allowance rate for the sample of AI-related cases.

Human Activity Terms
Human activity terms had significantly lower allowance rates (approximately 10% lower) than the average allowance rates for the AI sample. Although the term "game" appeared to have boosted allowance rates when present in the independent claim, the boost was only up to 73.2%, which is still well below the average allowance rate for the sample of AI-related cases.

Squishy Puffery Terms
Terms that were either squishy or mere puffery were grouped together as "squishy puffery terms." These terms also had significantly lower allowance rates (approximately 10% lower) than the average allowance rates for the AI sample. In particular, the term "smart" had an allowance rate of 63.8% when present in the title, abstract, or claims, and an allowance rate of 54.4% when present in the first independent claim. The lesson: calling a system or device "smart" is not wise in a patent claim. Instead, the drafter should focus on the characteristics or functions of the system or device that make it smart.

Finance Terms
Last and least, finance terms made it more difficult to obtain allowance of a case in the sample of AI-related cases. For example, the term "business" had an allowance rate of 58.5% when present in the title, abstract, or claims, and an allowance rate of 52.7% when present in the first independent claim. If you are describing or claiming a business method, this data suggests that, if possible, you should focus on the aspects of the invention that are least related to business methods and more related to the other categories above.

9. CLAIM LENGTH CONSIDERATIONS FOR AI CASES
As explained in this article covering a larger study of claim lengths for software-related claims, avoid drafting extremely short patent claims. AI itself is not new, and you need a fair amount of detail in your claims in order to distinguish your invention from the prior art. How short is extremely short in software patent claims? According to the prior study, about 300 characters, though not all AI-related claims are software claims.
Some of the granted composition of matter and pharmaceutical-related claims in the AI dataset were incredibly short. Claim length appears to be irrelevant for composition of matter and pharmaceutical-related cases.
For method claims in the AI dataset, the average claim length as filed was 163 words for granted cases versus 152 words for abandoned cases. 1.4% of the granted cases started with method claims that were less than 300 characters, versus 3.5% of the abandoned cases. Only two method claims (0.05% of the 3888 granted method claims in the sample) were granted with fewer than 300 characters. Both had 297 characters. One was a method of treatment claim, and the other was a rare software claim granted with less than 300 characters.
The extremely short method of treatment claim (U.S. Pat. 10,265,497) reads:
"A method for treating dementia in a subject in need thereof, the method comprising: administering a non-invasive stimulus to the subject to induce synchronized gamma oscillations in at least one brain region of the subject to treat dementia in the subject."
The extremely short software claim (U.S. Pat. 9,460,365) reads:
"A method comprising:
compressing color values using a palette based encoder;
finding clusters of color values and encoding color values within the cluster with respect to a color value having a predefined characteristic; and
encoding clusters that have pixels or samples with constant color value."
As concluded in the prior study, applicants on average spend about $10,000 pursuing extremely short software claims. If the client and attorney are spending their time and effort pursuing efficient and realistic outcomes, neither would encourage the pursuit of extremely short software claims for the 0.02% chance that the strategy succeeds. Instead, patent attorneys should add context to claims that start out extremely short. The context will be helpful for the patent office to understand where to search and what to search for.
10. PRIORITY ISSUES FOR AI CASES
Beware of intervening prior art published between your provisional application filing and your non-provisional application filing, as there is a reasonable chance the provisional application does not support the non-provisional filing. The intervening prior art can invalidate your patent unless your provisional application discloses the invention you end up claiming in your non-provisional application. How likely is it that a non-provisional application will be unsupported by the parent provisional application? Higher than you think. See Guest Post by Eric Sutton: Do You Know What Your Provisional Application Did Last Summer? (Patently-O, Nov. 9, 2017).
Of the 27,272 AI patent applications, a staggering 17,097 (62.7%) had filing dates that were not the same as the priority dates. The provisional application study found that 26.7% of provisionals miss 25% or more of the uncommon word stems of the first claim of the non-provisional. If we assume a non-provisional application lacks priority when the provisional application only describes about 75% of what is claimed, it is likely that at least 4,565 of the AI-related applications (26.7%) would lose their priority date. That could be devastating given the frequency by which AI-related innovations are now being published.
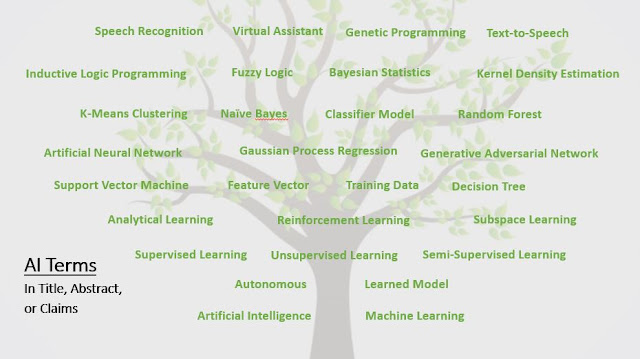
- artificial intelligence
- machine learning
- autonomous
- learned model
- supervised learning
- unsupervised learning
- semi-supervised learning
- analytical learning
- reinforcement learning
- subspace learning
- support vector machine
- feature vector
- training data
- decision tree
- artificial neural network
- gaussian process regression
- generative adversarial network
- k-means clustering
- naive bayes
- classifier model
- random forest
- inductive logic programming
- fuzzy logic
- bayesian statistics
- kernel density estimation
- speech recognition
- virtual assistant
- genetic programming
- text-to-speech
In future studies, I am happy to grow or shrink this list or use AI to generate the list of terms or find similar patent applications based on an initial seed of AI patents or terms. It is helpful that CPA Innography outputs not just the application serial number, but also the first claim.
Next, I imported the application serial numbers from CPA Innography into LexisNexis PatentAdvisor to determine the prosecution status information as well as law firm and examiner information.
I used a standard k-means clustering algorithm on the claims from CPA Innography to determine the eleven resulting clusters. The clustering algorithm looks for a specified number of clusters and outputs which cases are in each cluster as well as the claim terms that best define those clusters as distinct from other clusters. I configured the clustering algorithm to look for twelve clusters and then merged two adjacent clusters that were similar in terms of metrics (allowance rates within 1-2%) and claim terms (with only a one-term difference) present in the cluster.
I used a standard word stemming algorithm on the claims from CPA Innography to determine term frequencies in the issued patents and term frequencies in the abandoned applications. I calculated the allowance rates for each term based on their relative frequencies: freq (issued patents) / (freq (issued patents) + freq (abandoned applications)). I combed the data to remove unintelligible terms (e.g., due to missing spaces or extra spaces in the claims, or formulas in the claims) after the word stemming algorithm had run. I applied frequency thresholds and allowance rate thresholds to find terms that occurred in more than 1% of the sample to ensure that the data was interesting. Then, I expanded to similar terms, allowing for frequencies of as low as about 0.5% of the sample if the terms were closely related. Unlike the other parts of this study, the word-stemming portion was driven by my personal judgment on the clustering and strength of relationship among the terms in light of known laws that affect the patentability of certain types of inventions. The results of this mixed portion of the study were consistent with the machine-determined clusters in that clusters with human-performed aspects and terms that implied human performance both had significantly lower allowance rates than the sample as a whole.
4. HIGH-LEVEL METRICS FOR AI CASES
As a result of searching in Innography for the AI keywords (see above) in the title, abstract, or claims of U.S. applications filed and with priority post-Alice (6/20/14 and later), I found 24,848 applications related to artificial intelligence, of which 8,726 were finally disposed (1,546 abandoned and 7,180 granted). The remaining 16,122 are still pending. The allowance rate for the finally disposed cases was 82.3%.

The sample was divided into patented AI cases and abandoned AI cases, and the chart below shows examiner and art unit allowance rates for the two different groups. Higher examiner and art unit allowance rates are more likely to be associated with the patented cases than the abandoned cases, as one would expect. This shows that examiner and art-unit variability likely has some effect on the likelihood of allowance, even within the realm of artificial intelligence.

5. IMPACT OF THE 2019 REVISED PATENT SUBJECT MATTER ELIGIBILITY GUIDANCE
Since Feb. 2019, the allowance rate for AI-related applications is 82.2%, which is almost identical to the allowance rate for the full sample. Based on this finding, I concluded that the Guidance had little overall impact on the allowance of AI-related applications. That said, I was surprised to see so many cases finally disposed this year. That is perhaps because the filing rate of AI cases increased considerably over the span of the sample.

PatentAdvisor provides a Normalized Law Firm field. The tool gathers the representative agent data from the Patent Application Information Retrieval (PAIR) database and cleans up the agent data to address minor law firm misspellings. Because of this feature, law firm data can be easily viewed and compared.
A. Allowance Rates For Law Firms' Cases In The AI Sample
The sample of 24,848 AI-related cases determined in Innography (8,726 of which were finally disposed (see Section 4 above)) were imported into PatentAdvisor, and the Normalized Law Firm field was exported along with the case status, the number of OAs (Office Actions), and the number of RCEs (Requests for Continued Examination). The allowance rate was determined by dividing the number of granted cases by the number of finally disposed cases (granted and abandoned) for each Normalized Law Firm. The average OAs and average RCEs were determined by averaging the number of OAs and RCEs for each application (both pending and finally disposed applications) mapped to the same Normalized Law Firm. The charts below also show average OAs and RCEs for just the finally disposed cases mapped to the same Normalized Law Firm.
When sorting the data by allowance rate, some firms had allowance rates above 90%, while other firms had allowance rates as low as 0-63%. The chart below shows the highest allowance rates for law firms with more than 25 applications granted the AI sample. As shown, Mahamedi IP Law LLP Uber, Lempia Summerfield Katz, Young Basile, Wolfe Sadler Breen Morasch & Colby, Wilson Sonsini Goodrich & Rosati, and Ryan Mason & Lewis all had allowance rates of 100% for the sample, with 25-40 cases finally disposed. Also impressive were Tutunjian & Bitetto, Sheridan Ross, and Greenblum & Bernstein, with allowance rates near 100%.

Note that allowance rates are not always in control of the law firms. For example, a law firm may have a lower allowance rate if the law firm is prosecuting difficult cases or cases targeting marginal innovation, or if the law firm is working with clients who insist on abandoning cases despite good drafting and potentially good value (often due to changing business needs and financial capabilities). The client is often making the final decision on whether to pursue or abandon a case, and, to that end, the law firm is merely carrying out the client's instructions. That said, the allowance rate is impacted by the law firm, as the law firm drafts cases and is charged with zealously representing clients during prosecution with the USPTO.
Some law firms did not have as many granted cases in the sample of 8,726 finally disposed cases. Since the AI sample is a small subset of the hundreds of thousands of applications filed at the USPTO each year, it is important to understand that many of these law firms handle a wide variety of cases that include AI-related cases and likely also large sets of cases not related to AI. The chart below shows PatentAdvisor's "Normalized Law Firms" with 5 or more abandoned cases, sorted by the lowest allowance rates for the AI sample, after excluding known non-firms. As shown, Enceladus IP and what PatentAdvisor has listed, in the “Normalized Law Firm” field, as “Loza & Loza LLP Qualcomm” each had allowance rates of 0% for 7 finally disposed cases in the sample. Intelink Law Group, Hovey Williams, Sinorica, McClure Qualey & Rodack, and Browdy & Neimark had allowance rates of less than 50% for their cases that were in the sample. Hamre Schumann Mueller & Larson, K&L Gates, and LRK Patent Law Firm fared slightly better with allowance rates between 50 and 60% for finally disposed cases in the sample.
The chart below shows PatentAdvisor's "Normalized Law Firms" with 10 or more abandoned cases, sorted by the lowest allowance rates for the AI sample, after excluding known non-firms. As shown, Stevens Law Group and Muncy Geissler Olds & Lowe had allowance rates between 60% and 70% for their cases that were in the sample. Marbury, Knobbe Martens Olson & Bear, Schwegman Lundberg & Woessner, Oblon, and Sughrue Mion had allowance rates between 70% and 80%, which is near the average allowance rate for the USPTO. Norton Rose Fulbright fared better with an allowance rate of 80%, which is very close to the average allowance rate for the cases in the AI sample. As discussed above, there are many reasons outside of a law firm's control for why a law firm could have a lower allowance rate in the AI sample.

B. Average Pendency For Law Firms' Cases In The AI Sample
As explained above, the sample of 24,848 AI-related cases determined in Innography were imported into PatentAdvisor, and the Normalized Law Firm field was exported along with the case status, the number of OAs (Office Actions), and the number of RCEs (Requests for Continued Examination). The average OAs and average RCEs were determined by averaging the number of OAs and RCEs for each application (including both pending and finally disposed applications) mapped to the same Normalized Law Firm. The average OAs and average RCEs for only the finally disposed cases are listed separately.
Office actions include communications from the patent office rejecting the claims or objecting to the claims. They typically require a response on the part of the applicant to either change the claims in light of the rejection or objection, or to explain/argue why the rejection or objection was erroneous.
Requests for Continued Examination are required to continue the back-and-forth discussion with the examiner, typically to further amend the claims, after an applicant has reached a final office action. RCEs may also be required to submit newly discovered information in an information disclosure statement, or for other reasons that are outside of the law firm's and applicant's control. Each RCE costs $1300-$1900 for large entities, but only $325 to $475 for micro entities. Different firms may, on average, serve clients who are more or less sensitive to RCE costs. This would certainly affect the firms' pendency stats (below).
The number of OAs and number of RCEs is sometimes used to roughly approximate the cost of a patent application, with average office action fees; however, different law firms charge different amounts for different tasks. For example, some law firms could charge $2000 per office action; while others could charge $6000 per office action. Some law firms charge separately for examiner interviews, while others include interview charges in a fixed-fee office action reply. For these reasons, the number of OAs and number of RCEs is not a very good approximation of cost unless you understand the law firm's practices as well as the client's policies, or unless there is a more established norm in the industry or at least among candidate firms.
Note that the number of OAs and RCEs included OAs and RCEs for pending and finally disposed (granted or abandoned) published applications. For that reason, applications in the sample that were recently published (and likely recently filed) may not have yet received many office actions. Other applications may be long-pending but never finally disposed for a variety of reasons. For example, see this article by Chad Gilles about an unusual RCE strategy. To mitigate this effect, the charts below separately list average OAs and average RCEs that occurred in just the finally disposed cases, even though the charts are sorted based on average OAs that occurred in all applications, pending and finally disposed.
Also recall that the AI sample is cut off in the sense that it includes cases filed and having priority June 20, 2014, and later (but not earlier). The currently longest pending cases at the USPTO are cases filed before June 20, 2014, but these cases were outside of the AI sample's range.
As a result at least from counting pending cases and cutting off the sample at June 20, 2014, and in light of the limited sample size, the pendency statistics presented herein should not be used to estimate the actual number of office actions expected in a given scenario with a given firm. Those numbers should instead be calculated based on factors known and specific to the given scenario, with an understanding that there is a lot of variance in these numbers case to case.
When sorting the Normalized Law Firms by the number of office actions (least to greatest), top firms received, on average, less than one office action from the patent office. Other firms received, on average, between two and three office actions or objections from the patent office. As shown in the chart below for the most efficient firms in the AI sample with greater than an 85% allowance rate and 25 issued cases, Hauptman Ham apparently had many first action allowances, with averages of 0.19 office actions per application and 0.33 per finally disposed application. Also impressive were Dinsmore & Shohl, McDonnell Boehnen Hulbert & Berghoff, Harness Dickey & Pierce, Kilpatrick Townsend & Stockton, and Fenwick & West, who all averaged less than 0.9 office actions per application in the AI sample and around 1 office action per finally disposed application in the AI sample. Also as shown, Greenblum & Bernstein, Schox, Barnes & Thornburg, and Dority & Manning all had excellent average pendencies of just under 1 office action per case and between 1 and 2 office actions per finally disposed case.

Note that the number of office actions and RCEs are not always in control of the law firms. For example, a law firm may have more office actions if the law firm is prosecuting difficult cases or cases targeting marginal innovation, or if the law firm is working with clients who insist on pursuing cases despite reasonable arguments from patent examiners (often due to the high importance and value of the case). The client is often making the final decision on whether to continue prosecution, but the number of office actions and RCEs may also be impacted depending on how the law firm drafts and prosecutes the case.
As noted above, many of these law firms handle a wide variety of cases, with a small subset being the AI-related cases in this sample. The chart below shows PatentAdvisor's "Normalized Law Firms" with 10 or more total cases, sorted by the highest average number of office actions for the AI sample, after excluding known non-firms. As shown, Rogitz, Ference, Dorian Cartwright and Bookoff McAndrews PLLC averaged near 2.5 office actions per case (between 2.4 and 2.58 office actions per case) in the AI sample. Artegis Law Group LLP Harman, Blakeley Sokoloff Taylor & Zafman, and Cascadia Intellectual Property averaged between 2.13 and 2.33 office actions per case in the AI sample; whereas, Thomas D. Harvey and Squire Patton Boggs averaged just above 2 office actions per case in the AI sample. Note again that the AI sample was sorted based on the average number of OAs ("Ave. OAs") in both pending and finally disposed (granted or abandoned) published applications, and the "Ave. OAs Finally Disposed" column includes the average number of OAs only for the finally disposed cases handled by the corresponding Normalized Law Firm in the sample.

7. TOP CLAIM LANGUAGE CLUSTERS
As explained above, this study employed a standard k-means clustering algorithm on the claims from CPA Innography to determine eleven resulting clusters. The clustering algorithm was applied to the first claim only and was blind to allowance rates, examiners, and art units. The clustering algorithm identified 11 clusters, which I have named based on the top keywords the algorithm identified for each cluster: Self-driving cars, medical imaging, neural networks, cloud services infrastructure, IoT, training and using a ML model, speech recognition, application functionality, content management, signal and image processing, and user interaction.
The top keywords for each cluster are ordered by the algorithm in terms of importance to defining the cluster as a separate cluster. For that reason, when naming the clusters, I focused mostly on the most defining keywords (occurring earlier in the list) and secondarily on the remaining keywords. Some keywords defined multiple clusters. Keywords occurring in more than 3 clusters were filtered out because they were not as helpful for understanding the cluster among the other clusters. Although I listed keywords that occurred 2-3 times, I focused mostly on the keywords that were unique to the cluster.
All clusters and top keywords were computer generated without human input. The charts below combine the cluster and keyword information with examiner statistics and art unit statistics from LexisNexis PatentAdvisor to provide unique holistic insights into prosecuting AI-related patents. One of the most surprising findings of this study, as is evident from looking at the charts below, is that observed allowance rates for AI-related applications in many clusters of the sample were well above the examiner and art unit allowance rates corresponding to where applications in the cluster were being examined. This finding contradicts the teaching of some tool vendors who suggest the outcome of a case is mostly dependent on the patent examiner.
The first chart below shows, for the top 4 clusters sorted by allowance rate ("Allow. Rate"), the prosecution statistics as well as the key terms determined by the clustering algorithm. As shown, the average examiner allowance rate ("Examiner Allow.") and average art unit allowance rate ("Art Unit Allow.") result from averaging the allowance rates for the examiners or art units for cases from the sample that were in the corresponding cluster. The examiner and art unit allowance rates are different from the actual observed allowance rates for cases in the sample because examiners and art units handle many cases outside of each corresponding cluster of the sample. Some of the cases outside of the cluster of the sample are likely cases filed on similar topics pre-Alice; whereas, other cases outside of the cluster of the sample are likely cases filed on similar or different topics and not apparently related to AI. The individual clusters are discussed in more detail below.

I named the first cluster "self-driving cars" due to the top distinct claim terms in the cluster. The claims in that cluster clearly relate to autonomous vehicles driving on a road, as automatically determined by the clustering algorithm. Surprisingly, the 915 cases in this cluster had an allowance rate of 90.9%, which is significantly above the average for the sample. Also surprisingly, the average examiner allowance rates for the "self-driving cars" cases was 74%, which is below the average allowance rate for patented cases in the sample (despite the actual allowance rate being much higher). That said, the examiner allowance rate was still the highest among the clusters, and the art unit allowance rate was among the highest. This suggests that the self-driving cars cases (as well as other AI-related cases) are not consistently getting routed to the same group of examiners within the USPTO. If they were, the average examiner allowance rates would be closer to the observed allowance rates for the sample (in this case, 90.9%). Not surprisingly, patent eligibility issues rarely come up for the self-driving cars. From an Alice perspective, based on the data below, one could assume this area is generally quite technical.
Medical Imaging
I named the second cluster "medical imaging" because "medical" and "region" were uniquely defining to the cluster, and because other words in the cluster also fit within this paradigm. Although the observed allowance rate and average art unit allowance rate are very high, the examiner allowance rate is actually low. This means that medical imaging AI-related cases are getting routed to lower allowance examiners within art units but still getting allowed at a very high rate anyway. This also means that these examiners likely see a wide variety of technology, most of it having significantly lower allowance rates.
Neural Networks
I named the third cluster "neural networks" because it was the only cluster defined by the keyword "neural," and because other top keywords such as "network" and "layer" were consistent with this characterization. The allowance rates for neural network cases were high, despite very low examiner allowance rates, averaging 55.3% (second lowest among the clusters). Although these cases saw a slight rise in 101 rejections over medical imaging and self-driving cars, the vast majority (77.1%) still did not receive a 101 rejection during prosecution.
Cloud Services Infrastructure
The fourth cluster was challenging to pin down, as the keywords included many terms that are basic to many AI-related cases. That said, it was the only cluster defined by Cloud, and the top keywords "Service," "Request," "Network," and "Provider" fit cleanly within the field of cloud services infrastructure. These cases had a very high rate (30.2%) of 101 rejections, and low examiner and art unit allowance rates. Normally, that would lead one to believe that the observed allowance rate is also low. In this case, however, the allowance rate of 84.1% is higher than the average for the sample. This cluster is yet another indication that examiner and art unit allowance rates are not controlling the allowability of AI-related cases.

The fifth cluster is clearly related to IoT, with "signal," "power," "robot," "controller," and "position," and even "NAN," presumably "Neighborhood Area Network." This cluster had fairly average stats among the AI-related clusters, except that cases in this cluster were least likely (10.4%) to experience a 101 rejection during prosecution. IoT-related inventions are generally very device-oriented, and it makes sense that cases in this cluster would generally pass muster under Alice.
Training and Using A Machine Learning Model
Two clusters were combined together to form the cluster named "training and using a machine learning model." One cluster was slightly more focused on training, and the other cluster was slightly more focused on using. That said, the keywords and statistics for both clusters were nearly identical. For the purposes of this study, they were merged, even though they may exhibit other differences in future studies. These cases had average allowance rates with very poor examiner, art unit, and 101 statistics. I expect that this cluster could be broken down into 10-20 further clusters with another layer of clustering in a future study. As it is, it is difficult to draw any conclusions from the general language that defines this cluster.
Speech Recognition
The seventh cluster has "speech" and "recognition" as two of the top three keywords that define the cluster. It is clear what that this cluster represents AI innovation in the area of recognizing words and meaning from spoken words. It also makes sense that this cluster has the highest rate of 101 rejections (a whopping 39.5%) among the clusters, as speech recognition in the abstract is typically a human-performed task. Also, the way humans recognize speech has some parallels to the way computers recognize speech. The human brain breaks up sounds into parts and associates those parts with meaning. When drafting a patent related to speech recognition, Alice should be considered during the drafting phase. Although there is a high rate of 101 rejections, the allowance rate for this cluster is still 78.6%, which is near the average for the overall sample. This may be partially due to favorable routing at the patent office. These cases are being routed to high allowance art units, which is helpful when dealing with 101 rejections.

Application Functionality
The eighth cluster relates to "application," "interface," "mobile," and "behavior," which has been packaged here as "Application Functionality." As would be expected by thinking of parallels within art unit 3600 independent of the AI realm, the rate of 101 rejections is relatively high (32.0%), and examiner allowance rates are relatively low (59.5%) for this cluster. That said, the AI-related cases seem to be making it through at a rate of 76.2%, which is very close to the average allowance rate across the entire patent office.
Content Management
The ninth cluster, named "content management," relates to "content," "media," "digital," and even "CLM," which presumably refers to "content license management." The rate of 101 rejections is very high (second highest among the clusters at 37.1%), with low examiner and art unit allowance rates and also relatively low observed allowance rates. Because the allowance rate of 74.9% is currently slightly below the patent office average, I would steer an application away from this cluster of AI-related technologies if practical.
Signal And Image Processing
The tenth cluster is defined by "signal," "image," and "energy," which likely places it in the realm of signal and image processing. Although this cluster does not see a high rate of 101 rejections, it still experiences a relatively low allowance rate for AI-related cases. It seems like the tie between this cluster and AI-related technologies is weak, and I would steer an application away from this cluster if practical.
User Interaction
This cluster is related to user interfaces, but it does not seem closely related to AI technologies. In order to occur in the sample, a case would need one of the AI-related keywords in the title, abstract, or claims. With low allowance rates of 71.8% and high rates of 101 rejections, this is the worst overall cluster. That said, an allowance rate of 71.8% is still not too bad in light of the average examiner allowance rates of 54.7%. This suggests that the AI-related technology potentially in these cases was helpful in securing patent protection.
8. TOP CLAIM TERMINOLOGY
As discussed above, I used a standard word stemming algorithm on the claims from CPA Innography to determine term frequencies in the issued patents and term frequencies in the abandoned applications. As used in this study, the "allowance rate of a term" is the number of granted cases that include the term in the first claim divided by the number of finally disposed cases (including granted cases and abandoned cases) that include the term in the first claim.
Unlike the other parts of this study, the word stemming portion was driven by my personal judgment on the clustering and strength of relationship among the terms in light of known laws that affect the patentability of certain types of inventions. My goal in this portion of the study was to find all terms that were uniquely related to a similar concept, starting with the terms that occurred most frequently with the highest and lowest allowance rates.
The allowance rates of various terms, as presented below, are independent of the clusters discovered in section 7. The allowance rates in this section cover the occurrences of these terms across the entire sample of AI-related cases.
Self-Driving Terms
With self-driving cars coming in as the top AI-related cluster, in terms of allowance rate, I searched the list of word stems for terms that were closely related to self-driving cars. Not surprisingly, these terms all had very high allowance rates even though they sometimes occurred outside of the self-driving cluster. Most of these terms also boosted the allowance rates even higher when they occurred in the first independent claim instead of just in the focus (title, abstract, or claims).

Spatial Terms
Spatial terms such as "shape," "reach," and "along" were associated with higher allowance rates, particularly when present in the first independent claim. For example, cases with "along" in the title, abstract, or claims, on average, had allowance rates of 88.5%, and the allowance rate increased to 89.9% when "along" was in the first independent claim.

Data Distinction Terms
Although past studies have found data storage distinctions and container-related terms to be very helpful when present in the claims, they were only slightly helpful in AI-related cases, with "object" having a slightly higher allowance rate when present in the first independent claim.

There were several terms relating roughly to distributed networks, systems, or IoT that were frequent in the sample but with average allowance rates. Most notably, "status" had a higher allowance rate of 87.1% when present in the first independent claim.

Algorithm Terms
The more detailed algorithm terms, such as "neural," "anomaly," and "confidence" had higher allowance rates compared to the more general algorithm terms such as "algorithm" and "test." That said, most algorithm terms slightly boosted allowance rates when moved into the first independent claim as compared to just being in the focus (abstract, title, or claims).

Data management and conversion terms were associated with slightly lower allowance rates than the average allowance rates for the AI sample, and these terms were not very helpful in the claims.

High-Level Social Terms
High-level social terms were also associated with slightly lower allowance rates than the average allowance rates for the AI sample. In particular, the term "social" had a 67.5% allowance rate when present in the first independent claim. This is well below the average allowance rate for the sample of AI-related cases.

Human Activity Terms
Human activity terms had significantly lower allowance rates (approximately 10% lower) than the average allowance rates for the AI sample. Although the term "game" appeared to have boosted allowance rates when present in the independent claim, the boost was only up to 73.2%, which is still well below the average allowance rate for the sample of AI-related cases.

Squishy Puffery Terms
Terms that were either squishy or mere puffery were grouped together as "squishy puffery terms." These terms also had significantly lower allowance rates (approximately 10% lower) than the average allowance rates for the AI sample. In particular, the term "smart" had an allowance rate of 63.8% when present in the title, abstract, or claims, and an allowance rate of 54.4% when present in the first independent claim. The lesson: calling a system or device "smart" is not wise in a patent claim. Instead, the drafter should focus on the characteristics or functions of the system or device that make it smart.

Finance Terms
Last and least, finance terms made it more difficult to obtain allowance of a case in the sample of AI-related cases. For example, the term "business" had an allowance rate of 58.5% when present in the title, abstract, or claims, and an allowance rate of 52.7% when present in the first independent claim. If you are describing or claiming a business method, this data suggests that, if possible, you should focus on the aspects of the invention that are least related to business methods and more related to the other categories above.

9. CLAIM LENGTH CONSIDERATIONS FOR AI CASES
As explained in this article covering a larger study of claim lengths for software-related claims, avoid drafting extremely short patent claims. AI itself is not new, and you need a fair amount of detail in your claims in order to distinguish your invention from the prior art. How short is extremely short in software patent claims? According to the prior study, about 300 characters, though not all AI-related claims are software claims.
Some of the granted composition of matter and pharmaceutical-related claims in the AI dataset were incredibly short. Claim length appears to be irrelevant for composition of matter and pharmaceutical-related cases.
For method claims in the AI dataset, the average claim length as filed was 163 words for granted cases versus 152 words for abandoned cases. 1.4% of the granted cases started with method claims that were less than 300 characters, versus 3.5% of the abandoned cases. Only two method claims (0.05% of the 3888 granted method claims in the sample) were granted with fewer than 300 characters. Both had 297 characters. One was a method of treatment claim, and the other was a rare software claim granted with less than 300 characters.
The extremely short method of treatment claim (U.S. Pat. 10,265,497) reads:
"A method for treating dementia in a subject in need thereof, the method comprising: administering a non-invasive stimulus to the subject to induce synchronized gamma oscillations in at least one brain region of the subject to treat dementia in the subject."
The extremely short software claim (U.S. Pat. 9,460,365) reads:
"A method comprising:
compressing color values using a palette based encoder;
finding clusters of color values and encoding color values within the cluster with respect to a color value having a predefined characteristic; and
encoding clusters that have pixels or samples with constant color value."
As concluded in the prior study, applicants on average spend about $10,000 pursuing extremely short software claims. If the client and attorney are spending their time and effort pursuing efficient and realistic outcomes, neither would encourage the pursuit of extremely short software claims for the 0.02% chance that the strategy succeeds. Instead, patent attorneys should add context to claims that start out extremely short. The context will be helpful for the patent office to understand where to search and what to search for.
10. PRIORITY ISSUES FOR AI CASES
Beware of intervening prior art published between your provisional application filing and your non-provisional application filing, as there is a reasonable chance the provisional application does not support the non-provisional filing. The intervening prior art can invalidate your patent unless your provisional application discloses the invention you end up claiming in your non-provisional application. How likely is it that a non-provisional application will be unsupported by the parent provisional application? Higher than you think. See Guest Post by Eric Sutton: Do You Know What Your Provisional Application Did Last Summer? (Patently-O, Nov. 9, 2017).
Of the 27,272 AI patent applications, a staggering 17,097 (62.7%) had filing dates that were not the same as the priority dates. The provisional application study found that 26.7% of provisionals miss 25% or more of the uncommon word stems of the first claim of the non-provisional. If we assume a non-provisional application lacks priority when the provisional application only describes about 75% of what is claimed, it is likely that at least 4,565 of the AI-related applications (26.7%) would lose their priority date. That could be devastating given the frequency by which AI-related innovations are now being published.
11. CONCLUSIONS
The data generated by this study speaks for itself, and the reader is encouraged to draw her or his own conclusions. I believe the data suggests the conclusions stated in Section 2, but I would encourage readers to investigate the facts and draw their own conclusions after talking to at least one patent attorney.
ReplyDeleteYou finished certain solid focuses there. I did a pursuit regarding the matter and discovered almost all people will concur with your blog.
360DigiTMG
Great to become visiting your weblog once more, it has been a very long time for me. Pleasantly this article i've been sat tight for such a long time. I will require this post to add up to my task in the school, and it has identical subject along with your review. Much appreciated, great offer.
ReplyDeleteData analytics course
This is my first time visit here. From the tremendous measures of comments on your articles.I deduce I am not only one having all the fulfillment legitimately here!
ReplyDeletehrdf contribution
I will truly value the essayist's decision for picking this magnificent article fitting to my matter.Here is profound depiction about the article matter which helped me more.
ReplyDeletedata science course noida
Liên hệ Aivivu, đặt vé máy bay tham khảo
ReplyDeleteve may bay di my gia re
giá vé máy bay từ mỹ về việt nam
vé máy bay từ nhật về vn
chuyến bay từ frankfurt đến hà nội
giá vé máy bay từ Vancouver về việt nam
bay từ hàn quốc về việt nam
các khách sạn cách ly ở hà nội
You have provided valuable data for us. It is great and informative for everyone. Keep posting always about Patent Attorney Melbourne. I am very thankful to you.
ReplyDeleteYou have given us important information. It is fantastic and helpful for everyone. Continue posting custom erp
ReplyDeleteCongratulations! Excellent text in very clear, straight to the point words.
ReplyDelete